목적 : ROC CURVE 이해
AI 의 데이터 분류 기법 중 하나인 이진 분류(Binary Classification)를 알아보자.
분류모델은 이진분류(Binary Classification)와 다중 분류(Multi Classification)로 나누어 집니다.
이진분류 : 어떠한 대상에 대한 규칙이 참인지 거짓인지 판별
다중분류: 입력한 값에 따른 분류 카테고리가 세가지 이상
이진분류를 하는 기법에는 다양한 모델이 존재합니다.
sklearn (sciki-learn) 을 설치하여 내부에서 제공하는 라이브러리를 확인하면 샘플 모델들을 확인할 수 있습니다.
python에서 pip install scikit-learn 을 입력하고 바로 설치합니다.
디렉토리 : 'C:\파이썬폴더\Lib\site-packages\sklearn\datasets\
데이터셋들과 분류기들이 몇가지가 있음을 확인할 수 있습니다.
데이터셋을 기반으로 scikit-learn에서 라이브러리를 제공합니다.
라이브러리를 가져와서 코드를 돌려보도록 하겠습니다.
분류기 : RandomForestClassifier
데이터 : load_breast_cancer

위에 코드에서 roc_curve에 대한 파라미터도 확인을 할 수가 있습니다.
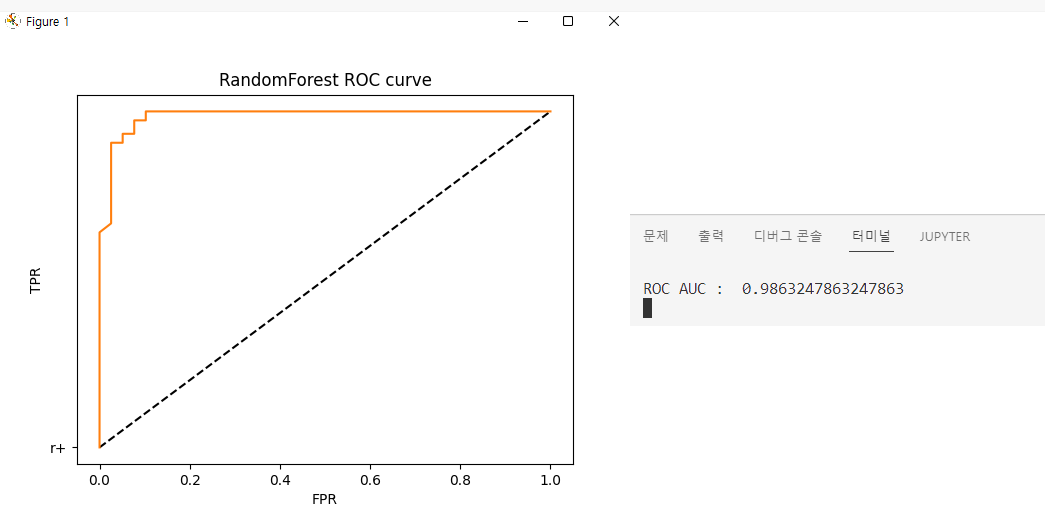
코드에 출력에 대한 결과로 위와 같이 확인이 가능합니다.
이제 이 그래프의 의미와 ROC-AUC 값이 무엇인지 확인하겠습니다.
ROC-AUC : ROC CURVE 면적에 대한 값으로 1에 가까울수록 이상적인 분류 성능에 가까워 집니다.
분류기에 데이터셋을 적용하여 참과 거짓을 판별하고 검증 과정이 필요한데 이를 확인하기 위한 것이 ROC-CURVE이며 위의 결과 값은 검증 및 성능을 측정하는 코드로 정리 할 수 있습니다.
이해를 돕기위한 아래 표입니다.
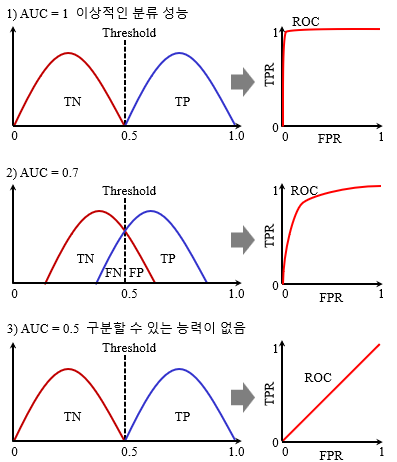
여기서 Threshold 값을 조정하면 그래프가 변하게 됩니다.
Threshold 값은 분류기와 데이터에 따라 적절하게 변경해야합니다.
이제 암진단에 대한 이진 분류 시스템에 관하여 TN, TP, FP, FN 이 무엇인지 확인해 봅시다.
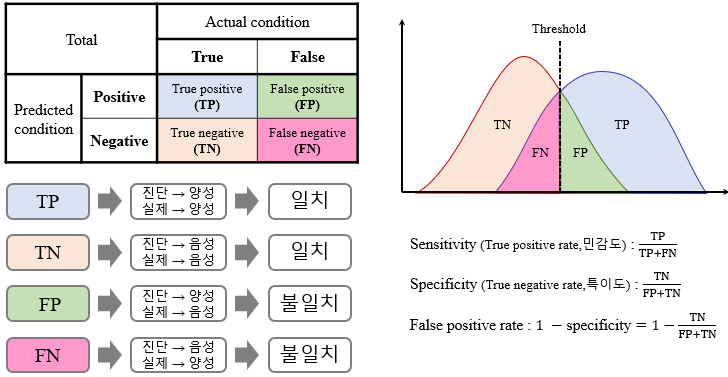
위에 내용을 이해하자면, 이진분류를 위한 검증을 위하여 일부러 맞지 않는 결과를 넣어 잘 찾는지 확인 하는 것입니다.
따라서 데이터들과 분류기마다 Threshold 값이 달라 질 수 밖에 없으며, 최적화 값은 존재 할 것입니다.
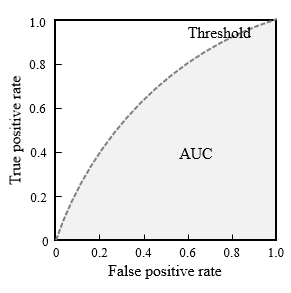
Threshold 의 최적화된 값을 넣었을때 AUC 값은 1에 가까워 지게 됩니다.
정리를 하자면,
이진분류에는 검증과정이 필요하다.
검증과정에는 ROC-CURVE가 있다.
분류기는 여러가지가 있다. (데이터셋마다 최적화된 분류기가 다를 것이다.)
AUC 의 값을 1에 도달시키는 Threshold 값이 있다. (이것 또한 데이터셋과 분류기의 조합에 따라 달라진다.)
결론
이진분류는 참과 거짓을 명확하게 나타내는 목적에만 사용됩니다.
예를 들면 시각, 청각에 해당 될 수 있습니다.
ex) 고양이 사진이 고양이 인지 강아지인지 판별
ex) 레이다가 물체를 감지했는지 안했는지 판별
ex) 남자 목소리인지 여자목소리인지 판별
등이 해당 될 수 있으며 확실한 결론을 도출할 필요가 있을 때 이진분류를 사용하며 이러한 이진분류 시스템을 만들었을 때 검증 및 성능을 평가 할 때는 ROC CURVE를 사용합니다.